Du bekommst regelmäßig aktualisierte Daten geliefert und musst erstmal herausfinden, was der Kunde geändert hat?
Natürlich ist nichts beschrieben oder markiert.
Bitte mach das nicht manuell…
Excel Dateien vergleichen und Unterschiede finden ist mit Python super einfach.
Und hier zeige ich dir, wie!
Wie kann ich mit Python Excel Dateien vergleichen?
Mit openpyxl kannst du Excel Dateien super einfach bearbeiten. Mit load_workbook öffnest du die Datei und kannst im auf die Arbeitsblätter zugreifen. Spalten / Zeilen Namen geben dir den Zugriff auf die Zellen. Zum Beispiel openpyxl.load_workbook('Datei.xlsx')['Arbeitsblatt']['D18'].value.
Einleitung
Im letzten Artikel haben wir uns ein paar Testdaten in eine Excel Datei generieren lassen.
Genau die Daten werden wir jetzt nutzen.
Wenn du den Artikel noch nicht gelesen hast, weißt du auch gar nicht wie schnell und einfach man Testdaten generieren kann!
Also klick direkt hier und hol das nach!
Alternativ habe ich dir die Daten natürlich auch wieder in das Git Repository gelegt und du kannst sie einfach herunterladen.
Vorbereitung
Wir brauchen nicht viel.
Die wunderbare Bibliothek openpyxl und ein paar Daten, die wir vergleichen können.
Nachdem du sicher ganz brav den letzten Artikel gelesen hast, hast du natürlich schon Testdaten in der Hand 😉
Dann lass uns direkt loslegen!
Wir gehen dabei davon aus, dass wir einfach nur Aktualisierungen bestehender Dateien bekommen.
Die Arbeitsblätter bleiben also unverändert, es gibt einfach nur Aktualisierungen der Daten in den Arbeitsblättern.
Das Tolle an openpyxl ist, dass es bestehende Excel Dateien bearbeiten kann.
Im Vergleich dazu würde Pandas eine neue Datei erzeugen.
Das ist besonders dann wichtig, wenn du bereits Formatierungen wie zum Beispiel farbliche Markierungen in deinen Arbeitsblättern hast.
Auch Formeln oder VBA Code würden von Pandas nicht behalten werden.
Mit openpyxl ist das kein Problem. Du bearbeitest einfach nur die bestehende Datei.
pip install openpyxlExcel Dateien einsammeln
Zuerst brauchen wir natürlich die Daten, die wir am Ende vergleichen wollen, auch in unserem Programm.
Dafür importieren wir zuerst einmal openpyxl.
Mit openpyxl können wir über die Funktion load_workbook() auch direkt eine Datei öffnen.
Ein workbook in openpyxl ist nichts weiter als eine Excel Datei mit einem oder mehreren Arbeitsblättern.
import openpyxl
old_file = openpyxl.load_workbook("old_file.xlsx", keep_vba=True)
new_file = openpyxl.load_workbook("new_file.xlsx", keep_vba=True)VBA ist immer eine nicht ganz ungefährliche Sache in Excel Dateien. Außerdem wird der Code noch gesondert innerhalb der Datei gehalten.
Deshalb wird der Code regulär von openpyxl nicht behalten.
Möchtest du explizit den VBA Code behalten, kannst du das Attribut keep_vba=True setzen.
Arbeitsblätter durchlaufen
Da wir alle Daten, in den Excel Dateien vergleichen wollen, müssen wir natürlich auch alle Arbeitsblätter innerhalb der Dateien durchlaufen.
Über das Attribut sheetnames bekommen wir eine Liste aller Arbeitsblätter geliefert.
Mit dem Namen kannst du jetzt auf die Datei zugreifen, wie du es mit einem Dictionary machen würdest.
Also zum Beispiel old_file['Arbeitsblatt 1'] liefert dir das Arbeitsblatt 1 zurück.
Wollen wir jetzt alle Arbeitsblätter in beiden Dateien durchlaufen, müssen wir nur die beiden Listen, die wir mit .sheetnames bekommen, gemeinsam durchlaufen.
Um zwei Listen gemeinsam zu durchlaufen, hilft uns Python mit dem Builtin zip().
for sheetname_old_file, sheetname_new_file in zip(old_file.sheetnames, new_file.sheetnames):
sheet_old_file = old_file[sheetname_old_file]
sheet_new_file = new_file[sheetname_new_file]Mit zip() bekommen wir das erste Element der ersten Liste und das erste Element der zweiten Liste zurückgeliefert.
Das geben wir dann in old_file und new_file und bekommen dafür das erste Arbeitsblatt aus old_file und das erste Arbeitsblatt aus new_file zurück.
Sehr schön, schon haben wir die Arbeitsblätter, die wir vergleichen wollen.
Spalten und Zeilen durchlaufen
Nachdem wir jetzt ein Arbeitsblatt in der Hand haben, müssen wir die Spalten und Zeilen durchlaufen.
Excel hat erstmal eine beliebige Anzahl an Spalten und Zeilen in einem neuen Arbeitsblatt.
Aber viele davon interessieren uns wahrscheinlich überhaupt nicht.
Sind zum Beispiel nur fünf Spalten und zehn Zeilen in der Datei, müssen wir ja nicht bis Spalte 500 und Zeile 50.000 vergleichen.
Der Rest ist leer.
Aber wie finden wir heraus, wie weit wir vergleichen müssen?
Natürlich könnten wir die Datei aufmachen und nachsehen und unseren Code anpassen…
Wirklich automatisch wäre das aber nicht.
Also greifen wir wieder auf openpyxl zurück.
Wir bekommen zwei einfache Attribute zur Hand:max_column liefert den letzten Spaltenindex zurück, der noch Daten enthält.max_row liefert den letzten Zeilenindex zurück, der noch Daten enthält.
Das einzige Problem, das jetzt noch bleibt, ist, dass die beiden Dateien natürlich unterschiedlich viele Spalten oder Zeilen haben könnten.
Bei einer Aktualisierung kann es ja durchaus sein, dass ein Datensatz dazu kam.
Als Nächstes müssen wir also herausfinden, welche der beiden Dateien mehr Inhalt hat.
Das Python Builtin max() ist alles, was wir dafür brauchen.
max_row = max(sheet_old_file.max_row, sheet_new_file.max_row)
max_column = max(sheet_old_file.max_column, sheet_new_file.max_column)Dann gehts jetzt endlich ans iterieren.
Von 0 bis max_column, bzw. von 1 bis max_column + 1 lässt sich über das nächste Builtin, range(), einfach umsetzen.
Warum sollten wir von 1 bis max_column + 1 rennen und nicht bei 0 anfangen?
0 wäre die erste Spalte. Und in unseren Daten aus dem letzten Artikel enthält die erste Spalte den Zeilenindex. Den wollen wir überspringen.
Gleiches gilt für die Zeilen. Die erste Zeile enthält die Spaltennamen, die wollen wir natürlich überspringen.
for col_idx in range(1, max_column + 1):
for row_idx in range(1, max_row + 1):In der ersten for-Schleife durchlaufen wir die Spalten, mit der zweiten Schleife durchlaufen wir die Zeilen.
Das heißt, für jede Spalte werden alle Zeilen in dieser Spalte durchlaufen.
Zellen vergleichen
Indem jede Zeile in jeder Spalte durchlaufen wird, bekommen wir immer einen Index an die Hand.
Mit den beiden Schleifen bekommen wir also zum Beispiel 1-1, also Spaltenindex 1, Zeilenindex 1 geliefert.
Mit dem Index können wir wieder an unser Arbeitsblatt gehen und die Zelle direkt via Index abgreifen.
old_cell_value = sheet_old_file.cell(column=col_idx, row=row_idx).value
new_cell_value = sheet_new_file.cell(column=col_idx, row=row_idx).valueDas Attribut cell() nimmt einen Spaltenindex und einen Zeilenindex entgegen und liefert uns dafür die Zelle zurück.
Eine Zelle ist wieder ein ganzes Objekt mit mehreren Attributen.
Eins dieser Attribute ist value. Damit bekommen wir den eigentlichen Wert der Zelle, also den Inhalt der Zelle, geliefert.
Was kommt jetzt?
Na ja, wir haben beide Zelleninhalte in der Hand, dann müssen wir sie vergleichen:
if old_cell_value != new_cell_value:Somit weißt du, ob sich die Werte unterscheiden oder nicht. Und uns interessieren ja nur die Zellen, die sich unterscheiden.
Was machen wir mit dem Wissen?
Unser Ziel war es, die Unterschiede auf den ersten Blick erkennen zu können. Der einfachste Weg das zu tun ist, die Zelle farblich zu hinterlegen.
Dafür bekommen wir von openpyxl das Objekt PatternFill.
Mit PatternFill können wir eine Füllung für die Zelle definieren. Zum Beispiel möchten wir eine Farbe festlegen, die einfach durchgehend ist.
Dafür wähle ich eine Farbe, die nicht in den Standardfarben von Excel enthalten ist.
Warum mache ich das?
Ganz einfach: Wenn ein Bearbeiter nett sein möchte und uns schon Änderungen markiert, oder aus anderen Gründen Markierungen gesetzt hat, wird in der Regel aus der Standard Farbpalette von Excel ausgewählt.
Indem wir eine eigene Farbe festlegen, ist es viel unwahrscheinlicher, dass wir zufällig Überschneidungen haben und unsere Markierungen wertlos werden.
from openpyxl.styles import PatternFill
marker_color = PatternFill(fgColor='00008080', fill_type='solid')Die Farbe ist vielleicht nicht schön, aber sie fällt auf und sie wird wohl kaum von jemandem gewählt werden.
Um die Zelle jetzt mit der Farbe zu füllen, setzen wir die Farbe an das Attribut fill der Zelle.
sheet_new_file.cell(column=col_idx, row=row_idx).fill = marker_colorFür die Markierung nehmen wir natürlich das sheet_new_file. Immerhin wollen wir ja wissen, was sich in der neuen Datei geändert hat.
Ergebnis Excel speichern
Als Letztes wollen wir unsere Ergebnisse noch speichern.
Damit wir unsere Original Excel Dateien nicht überschreiben, übergeben wir für den Aufruf von save() einfach einen neuen Namen.
Damit werden die ursprünglichen Daten nicht überschrieben und einfach eine neue Datei angelegt.
new_file.save('result.xlsx')
new_file.close()Das war’s.
Damit sind alle Änderungen in der neuen Excel Datei result.xlsx markiert und gespeichert.
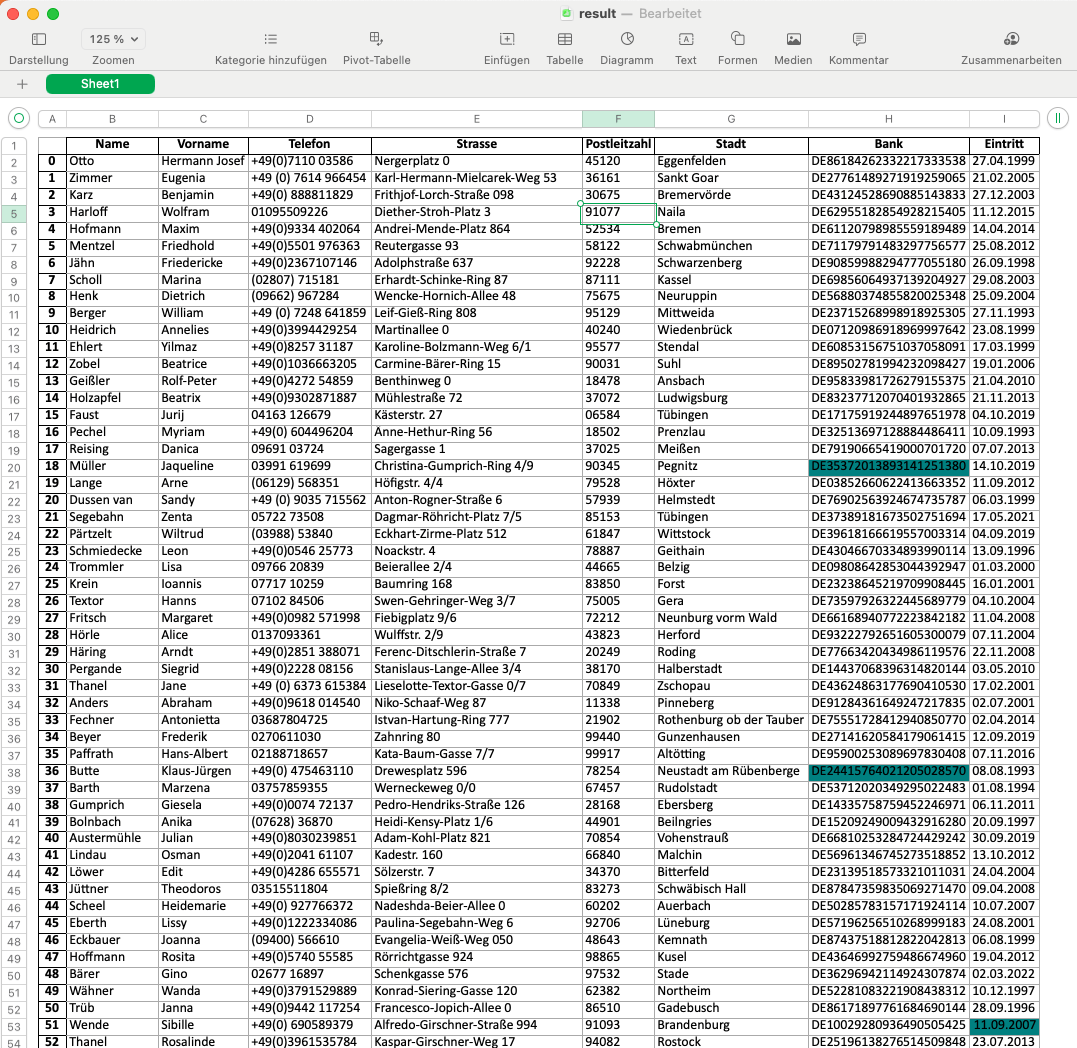
Zusammenfassung
Lass uns noch einmal kurz zusammenfassen:
- Zuerst musst du die Excel Dateien mit
openpyxlöffnen - Dann kannst du über das Attribut
sheetnamesdurch die Arbeitsblätter in der Datei iterieren. - Als Nächstes solltest du ermittelt, wie viele Spalten und Zeilen in deinem Excel Arbeitsblatt überhaupt gefüllt sind.
Das kannst du mit den Attributenmax_columnundmax_rowerledigen.
Wichtig ist das für die Performance. Du kannst dir unter Umständen tausende Durchläufe einsparen. - Jetzt kannst du über die Spalten und Zeilen iterieren und damit die Indexkombinationen für die einzelnen Zellen erhalten.
Die können dann über die Funktioncellan dem Arbeitsblatt genutzt werden, um den Inhalt der Zelle zu bekommen. - Ist das geschafft, brauchst du nur noch vergleichen und bei einem Unterschied die Zelle mittels
PatternFillfarblich markieren. - Als Letztes musst du nur noch die Ergebnisse in einer neuen Datei speichern. Fertig!
Herzlichen Glückwunsch!
In Zukunft wird es deutlich schneller gehen, wenn du neue Daten bekommst.
All die manuelle Arbeit gespart, da bleibt doch sicher Zeit für eine extra Tasse Kaffee oder Tee 😉
Den vollständigen Code habe ich dir wieder auf Github zur Verfügung gestellt.
Wenn du noch Fragen hast, dann schau gerne auf meinem Discord Server vorbei!
Hier sind Anfänger und Fortgeschrittene unterwegs und wir helfen uns gerne gegenseitig bei Fragen in unseren Programmen und Hürden beim Einstieg.

