Egal, ob du noch ganz am Anfang stehst, oder schon lange nach wertvollen Informationen tauchst, die richtige Ausrüstung ist der Schlüssel zum Erfolg in den endlosen Weiten des WebScraping. Deswegen wollen wir uns heute einen kurzen Überblick über die besten Webscraping Tools verschaffen. Die Suche und “Bergung” der Daten soll ja so reibungslos wie möglich vorangehen. Also schnapp dir einen Kaffee oder Tee und begleite uns beim Tauchgang durch die verschiedenen Tools.
1. ScraperAPI:

Unsere erste Station ist ScraperAPI, eine effiziente und benutzerfreundliche Plattform, die Dir das komplexe Prozedere des Webscrapings abnimmt. Egal ob Du mit Proxies jonglieren, mit unterschiedlichen Browsern arbeiten, CAPTCHAs lösen oder JavaScript-Inhalte rendern musst – ScraperAPI ist Deine umfassende Lösung. Du sendest einfach eine HTTP-Anfrage, und ScraperAPI kümmert sich um den Rest. Komfotabler geht’s kaum.
2. ParseHub:

Mit ParseHub sind auch große und komplexe Datensätze kein Problem mehr. Falls Du Dich jemals gefragt hast, ob sich Webscraping auch für komplexe und unstrukturierten HTML einsetzen lässt, dann findest Du mit ParseHub die Antwort. Mit der schönen Benutzeroberfläche lassen sich direkt die gewünschten Daten einfach auswählen.
ParseHub ist auch für Nicht-Entwickler geeignet.
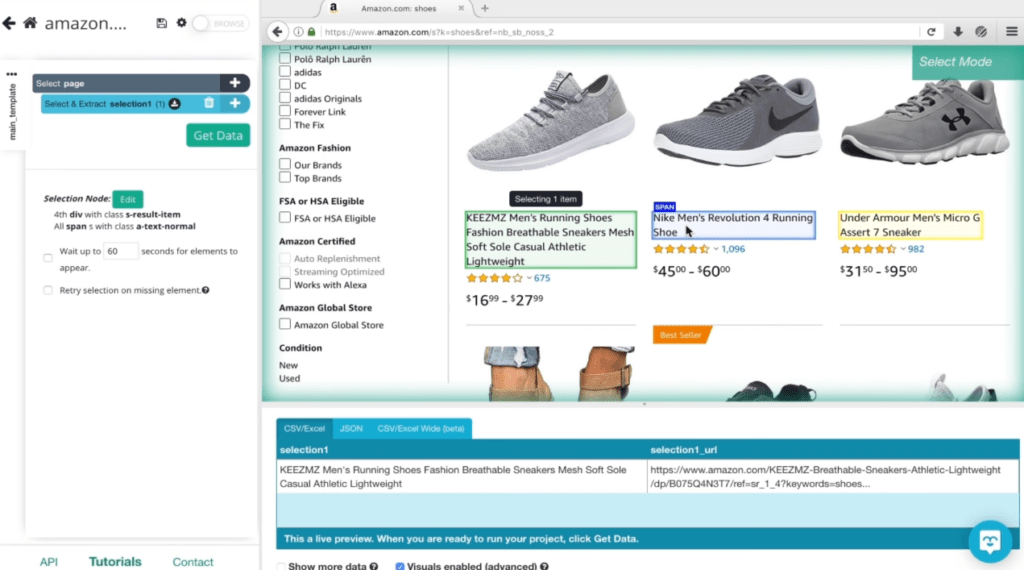
3. OctoParse:

Weiter geht unsere Tour mit OctoParse. Dieses Webscraping Tool punktet besonders durch seine Benutzerfreundlichkeit und sein breites Featureset, das sowohl Cloud- als auch lokale Datenextraktion erlaubt. Eine Fortbildung in Programmierung ist also keine Voraussetzung für das effektive Nutzen von OctoParse – ein wahrer Gewinn für alle Webscraping-Enthusiasten! Point&Click ist hier alles, was du drauf haben musst.
OctoParse ist auch für Nicht-Entwickler geeignet.
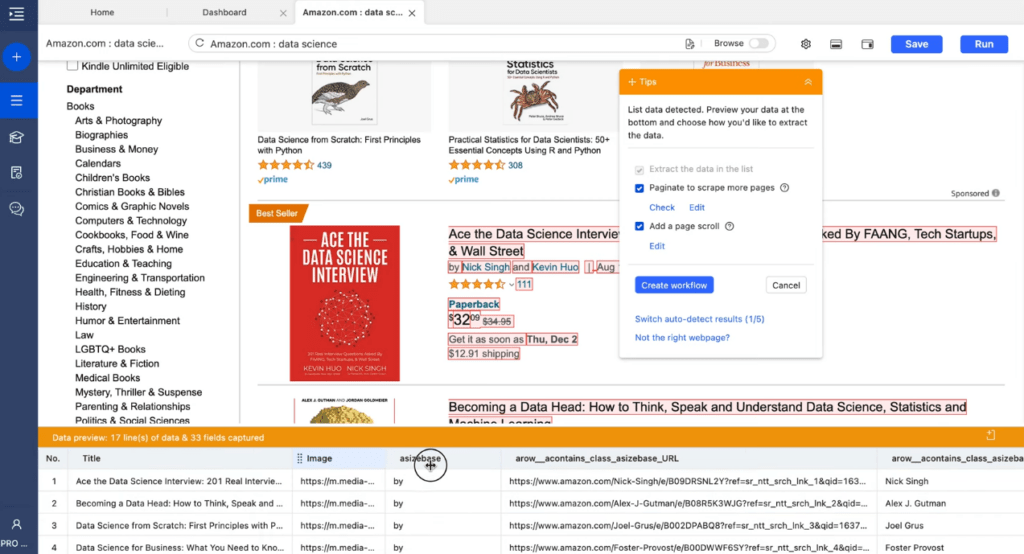
4. BrightData:

Hast Du schon einmal von BrightData gehört? Dieses Tool ist ein einmaliges Webscraping Werkzeug und bietet ein großes Portfolio an Proxies und Datenbereitstellungslösungen. BrightData zeichnet sich vor allem durch seine schnelle und zuverlässige Arbeitsweise und die Unterstützung von vielen verschiedenen Extraktionstechniken und -formaten aus. Ob Datacenter-Proxies, Residential-Proxies, Geo-Location oder ein ganzer Scraping Browser. Bei BrightData ist für so ziemlich jeden Anwendungsfall das richtige mit dabei.
5. ScrapingBee:

ScrapingBee ist ein weiteres effizientes Webscraping Tool, mit besonderer Kompetenz im Umgang mit JavaScript-Seiten, hinter einer CAPTCHA-Wand und anderen Herausforderungen des Webscrapings. Dieser in einer API eingekapselte Webscraping Dienst nimmt die Last des Managements von Headless-Browsern und Proxies ab, damit Du Dich auf das Wesentliche konzentrieren kannst: das Sammeln qualitativ hochwertiger Daten. Darüber hinaus bietet ScrapingBee einige nützliche Funktionen wie HTML-Rendering, JavaScript-Ausführung und die Möglichkeit, die Anfragen zu personalisieren, indem Du browserähnliches Verhalten simulierst.
6. BeautifulSoup:

Unsere Reise führt uns nun zu einem guten alten Bekannten – BeautifulSoup. In der Python-Welt ist BeautifulSoup ein echter Veteran und bekannt dafür, dass es Dir ermöglicht, Daten aus einem HTML-Dokument zu extrahieren, das wie ein Baum navigiert werden kann. Ein echtes Multitalent!
Hier auch noch ein Link zur Dokumentation, wenn du dich da durchschlagen möchtest.
7. Playwright:

Ein relativ neues, aber dennoch mächtiges Open-Source-Tool zur Automatisierung von Browsern finden wir mit Playwright. Mit Unterstützung für mehrere Browser (Chrome, Firefox, WebKit) und Funktionen wie automatischen Mausklicks, Tastatureingaben und sogar Uploads von Dateien, bringt Playwright das Webscraping auf ein völlig neuees Niveau. Seine größte Stärke ist jedoch die Interaktion mit dynamisch generiertem Content. Ein Bereich, in dem traditionelle Webscraping-Tools of an ihre Grenzen stoßen.
8. Selenium:

Last but not least besuchen wir Selenium, ein weiteres und sehr prominentes Mitglied der Webscraping Big Player. Ursprünglich wurde Selenium entwickelt, um automatisierte Tests für Webanwendungen durchzuführen, hat es sich aber inzwischen als unverzichtbares Tool für das Scraping von dynamisch geladenen Daten etabliert.
Die Wahl des richtigen Webscraping-Tools hängt vom Umfang und den Besonderheiten Deines Projekts ab. Aber egal welche Herausforderung auf Dich wartet, mit diesem Werkzeugkasten bist Du bestens gewappnet.
Leider kann ich dir hier kein „das ist das Beste“ anbieten. Es kommt beim Webscraping sehr auf die Quelle an. Dennoch kann ich dir meine Favoriten nennen.
- Für Nicht-Entwickler ist das ganz klar OctoParse. Die einfache Oberfläche und das Point&Click zusammenstellen der Daten sind einfach unschlagbar
- Für Entwickler (oder die Grenzen von OctoParse) ist Playwright mein Favorit. Es steht Selenium in nichts nach und lässt sich super einfach und angenehm entwickeln. In Verbindung mit Proxies von BrightData kommt man an so ziemlich alle Daten ran.
Du bist neugierig und willst direkt loslegen? Dann schreib dich direkt in unseren Webscraping Einsteiger-Kurs ein!
Und falls du eher der Bücherwurm bist, hab ich auch für dich eine Empfehlung mit im Gepäck:
- Web Scraping with Python: Collecting More Data from the Modern Web
- Hands-On Web Scraping with Python: Perform advanced scraping operations using various Python libraries and tools such as Selenium, Regex, and others
Dir wächst das Projekt über den Kopf, oder du möchtest es einfach erledigen lassen? Kein Problem! Wir stehen Dir mit unserem Webscraping Service zur Seite.
Bis zum nächsten Mal!

